인간의 사고 방식과 객체 지향
인간은 세상의 모든 것을 사물 단위로 바라본다.
산책을 나가서 주변을 둘러보라.
주위에 무엇이 보이는가.
당신이 사는 곳에 따라 다르겠지만, 일반적으로는 자동차, 나무, 행인, 아파트 등이 쉽게 보일 것이다.
인간이 세상을 인식하는 단위는 위와 같이 사물 단위다.
사물이라는 단어가 생명체가 아닌 물건을 뜻하는 의미로 생각될 수도 있다.
그렇다면 아래 검색 결과의 2번째 의미로 받아들이자.

객체 지향에서 말하는 객체가 위에서 말한 사물과 비슷한데,
이는 생명체와 비생명체를 모두 아우르는 포괄적인 개념이다.
int age = 87;
char* name = "Nicola Tesla";
int height = 188;
int birth_year = 1856;단순히 4개의 변수를 C로 작성하였다.
이를 조합하면 나이는 87이며 이름은 Nicola Tesla, 신장은 188, 출생연도는 1856인 인물임을 유추할 수 있다.
각 변수의 이름과 값을 하나씩 읽어가며 해당 변수들이 의미하는 바를 점진적으로 추론해 나가는 방식으로 읽은 것이다.
부분에서 전체로 나아간 것이다.
그러나 인간은 대상을 이런 식으로 인지하지 않는다.
전체를 먼저 생각하고, 보다 세부적인 부분으로 확장해 나가는 것이 직관적이다.
산책을 하면서 자동차를 볼 때, 바퀴가 4개이고 색상은 검정, 길이는 약 3.6m에 벤츠 로고가 새겨진 물체라고 인식하는게 아니라,
자동차가 있는데, 색상은 검정, 제조사는 벤츠. 비쌈.
이런식으로 대상을 부분이 아닌, 하나의 사물로서 인식할 것이다.
사물 단위로 인식하고, 관심 있는 정보만 빠르게 추출한다.
20층 높이에 복도식이며 엘리베이터가 존재하고, 경비실이 있으며 높이는 40m…
이게 아니다.
그냥 아파트라는 하나의 사물로 인식한다.
struct Person {
int age;
char* name;
int height;
int birth_year;
};
Person tesla = {
.age = 87,
.name = "Nicola Tesla",
.height = 188,
.birth_year = 1856,
};그래서 위와 같이 사물이 가진 속성을 모두 하나의 구조체로 묶어서 표현하는 방식을 일반적으로 사용하게 되었다.
속성이 많아지더라도 하나로 묶을 수 있기 때문에 구조체 명만 보고도 어떤 대상을 뜻하는지 직관적으로 파악할 수 있으며, 코드도 훨씬 깔끔해진다.
아래와 같이 여러 변수를 한 번에 반환할 수도 없지 않나.
int, char*, int, int new_person() {
int age = 87;
char* name = "Nicola Tesla";
int height = 188;
int birth_year = 1856;
return age, name, height, birth_year;
}물론 현재는 다중 반환이 가능한 Go언어라던가, 튜플을 통한 다중 반환 등이 존재하지만,
적어도 구조체라는 개념이 도입되고 C언어가 태동하던 시기에는 존재하지 않았다.
만일 존재 했더라도 변수가 너무 많아지면 쓸 데 없는 반복이 늘어나고, 반환값만 보고서는 의미를 파악하기가 어렵다.
((int, char*, int, int)라는 타입만 보고서는 이것이 무슨 의미인지 아무도 유추할 수 없을 것이다.)
위 코드는 그나마 new_person 이라는 함수명으로 유추가 가능하다지만,
그렇지 않은 경우를 생각해보면 감이 올 것이다.
따로 떨어지면 의미가 없어지는 데이터들을 구조체를 통해 하나로 묶어, 의미가 명확한 정보 단위로 치환하였다.
이것이 인간이 세상을 인식하는 단위에 가깝고, 보다 직관적이고 빠르게 코드를 이해할 수 있게 되었다.
그러나 이것만으로는 표현력이 부족했다.
사물은 다양한 속성을 가지면서 동시에 특정한 행위가 가능한 경우가 대다수다.
사람은 이름, 키, 나이, 성별, 출생연도 등의 속성을 가지며 먹다, 자다, 일하다 등의 행위가 가능한 대상이다.
자동차도 속성 외에 움직이다, 주유하다 등의 동작이 가능하다.
1995년에 탄생하여 현재도 주류로 활약중인 Java는 각 객체의 속성 외에도 동작을 추가할 수 있도록 설계되였다.
Java에서는 이를 메소드라고 부른다.
class Person {
int age;
String firstName;
String lastName;
int height;
int birthYear;
public void eat() {
System.out.printf("%s is eating\n", this.firstName + this.lastName);
}
public void sleep() {
System.out.printf("%s is sleeping\n", this.firstName + this.lastName);
}
public void work() {
System.out.printf("%s is working\n", this.firstName + this.lastName);
}
}언뜻 보면 그저 클래스 내부에 함수를 포함시킨 것이 전부인 것처럼 보인다.
eat(&person); // C
person.eat(); // Java그러나 표현력이 훨씬 더 좋아진 것을 볼 수 있다.
어떤 방식이 더 자연스럽게 읽히는지 비교해보면 명확하다.
국어로 치환해도 똑같다.
먹는다. 사람이.
사람이 먹는다.
주어, 동사 형태가 훨씬 더 자연스럽고 직관적이라고 느껴질 것이다.
또한 eat(&person) 은 먹는다. 사람을. 로 해석될 여지도 있다.
(위 케이스에서는 문맥 상 주어로 해석하겠지만, 인자가 주어인지 목적어인지 혼란을 주는 케이스도 상당수 존재할 것이다.)
Java에서는 메소드를 도입하여 C에서 동사, 주어 형태로 작성하던 코드를
자연스러운 문장을 읽듯 작성할 수 있다는 엄청난 장점을 얻었다.
작지만 아주 큰 차이라고 생각된다.
코드가 영어 문장처럼 직관적으로 읽히기 때문이다.
객체의 유효성
객체는 생성 시점부터 소멸 시점까지 항상 유효한 데이터를 가져야 한다.
그러나 우리가 작성한 Person 은 아직 생성자가 없기 때문에, 인스턴스화 하면 모든 멤버 변수가 비트 패턴이 0인 값으로 초기화 될 것이다.
이름은 없고, 키와 나이는 , 출생 연도도 0이다.
나이가 0이고 이름이 없는 것은 그럴 수 있다 쳐도,
출생 연도가 서기 0년 이거나 키가 0인 사람은 존재하지 않는다.(적어도 살아 있는 사람들 중에는)
즉, 유효하지 않은 데이터를 가진 객체가 생성된 것이다.
객체는 항상 생성부터 소멸 시점까지 유효한 데이터를 가져야 한다.
객체가 생명체인 경우는 사람이 태어나는 이미지를 상상하자.
아기는 태어날 때부터 키, 몸무게, 나이 등의 상태를 가지고 있을 것이다.
0이 아니다.
이전에 만들었던 Person 클래스에 생성자를 추가하여 인스턴스 생성 시부터 유효한 데이터를 갖도록 만들어보자.
class Person {
int age = 0; // 태어날 때 항상 0살이므로 기본값 0으로 설정
String firstName;
String lastName;
int height;
int birthYear = currentYear; // 현재 연도를 담은 전역 변수
public Person
(
String firstName,
String lastName,
int height
) {
this.firstName = firstName;
this.lastName = lastName;
this.height = height;
}
}
Person p = new Person("John", "Doe", 49);
p.age; // 0
p.firstName; // "John"
p.lastName; // "Doe"
p.height; // 49
p.birthYear; // 현재 연도이제 객체 생성 시에 반드시 인자를 넣어 모든 멤버 변수를 초기화 해야 한다.
그러나 여전히 유효하지 않은 값이 들어갈 수 있다.
new Person("John", "Doe", 99999);위와 같이 키를 99999 로 초기화 한다면?
키가 99999 인 사람은 존재하지 않기 때문에 비현실적이다.
이를 막기 위해서 생성 시부터 제약을 가해야 한다.
public Person
(
String firstName,
String lastName,
int height
) {
if (height < 0 || height > 300) {
// 유효하지 않은 키 입력 시 예외 발생
throw new IllegalArgumentException();
}
this.firstName = firstName;
this.lastName = lastName;
this.height = height;
}이제 키가 음수이거나 300 을 넘어간다면 유효하지 않은 값으로 인식하여 예외가 발생한다.
즉, 유효하지 않은 객체가 만들어지는 것이 방지된다.
비생명체인 경우는 공장에서 제품이 제조되어 나오는 이미지를 상상하자.
제품도 이미 공장에서 완성되어 나오고, 불량품은 버려질 것이다.
유효한 제품만 상품이 되는 것이다.
자동차, 휴대폰 등에 필요한 속성과 생성자를 직접 생각해보며 코드를 작성해보면 도움이 될 것이다.
객체의 의인화
현실에서는 사람이 자동차를 운전한다.
이를 코드로 표현하면 다음과 같을 것이다.
person.drive(car);그러나 객체 지향에서는 다음과 같이 표현하는 것이 일반적이다.
car.drive();마치 자동차가 인간처럼 스스로 움직이는 것 같은 표현이다.
객체 지향에서의 객체는 생명체던 비생명체던 모두 자아를 가지고 스스로 동작할 수 있는 존재라고 생각하자.
만약 현실에서 일어나는 일련의 과정을 코드로 완전히 동일하게 모든 것을 표현하려고 한다면.
person.pickUp(carKey); // 차 키를 집어든다.
person.put(person.carKey).in(car); // 집어든 차 키를 차에 꽂는다.
person.openDoorOf(car); // 문을 연다.
person.getIn(car); // 차에 탄다.
person.start(car); // 시동을 건다.
person.stepOn(car.pedal); // 엑셀을 밟는다.이렇게 말도 안 되게 장황해질 것이다.
쓸 데 없이 person 의 메소드가 수 배 ~ 수십 배는 더 추가될 것이고,
person , car 의 멤버 변수도 상당량 늘어나게 된다.
함수 호출과 메모리 소비량이 증가하여 프로그램의 성능도 저하될 뿐 아니라, 가독성도 나빠질 것이다.
자동차를 의인화하고 중간 과정을 생략하면 이를 car.drive(); 한 줄로 축약할 수 있기 때문에,
현실에서의 과정이 생략 되더라도 훨씬 합리적이다.
인간의 직관에 심각하게 반하지도 않기 때문에 이해하는데 어렵지도 않다.
때로는 너무 현실적이지 않은 것이 오히려 간단 명료하고 직관적으로 다가온다.
객체 지향의 4대 원칙
1. 추상화(Abstraction)
인간은 사물 단위로 대상을 인식하기 때문에 C에서는 사물이 가진 속성을 구조체로 묶어서 표현 했었고,
이후 Java, C++에 와서는 구조체에 동작까지 추가하여 클래스라는 이름으로 명명하게 되었다.
그렇다면 현실에 존재하는 대상을 코드로 옮기기 위해서, 우선 사물이 가진 속성과 동작이 무엇인지 생각하는 과정이 필요할 것이다.
그런데 과연 사물이 가진 모든 속성과 동작을 코드로 옮기는 것이 가능할까.

내연기관 자동차가 가진 부품 수가 약 3만 개에 달한다고 한다.
이 모든 것을 코드로 표현할 수 있을까.
아니, 그 전에 그럴 필요가 있을까.
중고차 거래 사이트를 만든다고 생각해보자.
과연 각 자동차를 판매 등록할 때, 3만 개의 부품 정보가 모두 필요할까.
만약 판매자가 중고차 판매 등록을 해야하는데, 모든 부품 정보를 모두 등록해야 한다면,
아무도 그 사이트를 이용하지 않으려 할 것이다.
앞서 사람이 자동차를 인식할 때 설명했던 내용을 다시 인용하겠다.
인간이 자동차를 보자마자 3만 개에 달하는 부품을 모조리 인지하는 것은 불가능하다.
그렇기에 무의식적으로 대부분의 정보는 생략하고,
관심 있는, 필요한 정보만 빠르게 추출한 것이다.
이렇게 하는 것이 훨씬 합리적이며, 코드로 작성할 때도 마찬가지일 것이다.
이쯤에서 추상화라는 단어의 의미에 대해 생각해보자.
추상화는 구체화의 반대말이다.
여기서 구체적인 것은 현실에 존재하는 실제 사물을 뜻할 것이다.
추상적인 것은 코드로 옮겨진 사물이다.
즉, 구체적인 것을 간략하게 만드는 과정을 뜻한다.
좀 더 풀어서 말하자면 현실에 존재하는 사물이 가진 속성 중에서 필요한 것만 추출하여 코드로 옮기는 것이라 할 수 있겠다.
이 과정 이전에 필연적으로 내가 작성하는 코드가 어떤 프로그램인지, 어떤 정보가 필요할지 먼저 생각하는 것이 동반되어야 할 것이다.
중고차 사이트라면 차량의 연식, 제조사, 모델, 가격, 상태, 사진 등이 필요할 것이다.
중고차 판매를 위해서 3만 개의 부품에 대한 세세한 정보 보다는,
위와 같이 대략적으로 차량의 상태를 나타내는 최소한의 정보만 추출하는 것이 쓸 데 없는 정보를 배제하여 메모리 낭비를 줄여주고, 사이트 이용자, 관리자 모두 우선순위가 높은 정보를 빠르게 인지할 수 있도록 만들어 줄 것이다.
이번에는 사람을 추상화 해보자.
마찬가지로 현실에 존재하는 모든 속성을 담을 필요는 없다.

60조 개의 세포에 대한 정보를 모두 필요로 하는 프로그램이 과연 존재할까.
최근 컴퓨터에 장착되는 메모리의 평균 용량이 8 ~ 16GB인데, 이를 byte로 환산하면 80억 ~ 160억 byte 정도가 된다.
세포 하나를 1byte로 구현한다고 쳐도, 사람 한 명의 데이터를 모델링 하기 위해서 이보다 수천, 수만 배의 메모리가 필요할 것이다.
현재로서는 대부분의 컴퓨터에서는 불가능하며, 불필요하다.
앞서 사람을 이미 추상화 했었다.
나이, 성, 이름, 키, 출생연도 5가지 속성과 먹다, 자다, 일하다 3가지 동작을 추출해서 말이다.
이렇게 반드시 필요한 정보만을 간추린 뒤, 프로그램에서 요구하는 정보가 추가되면, 그 때 확장하는 것이 훨씬 더 합리적일 것이다.
여기까지가 객체 지향에서의 추상화에 대한 설명이다.
그러나 추상화라는 용어는 객체 지향 뿐만 아니라 다른 곳에서도 사용되는데,
대표적으로 함수의 추상화가 있다.
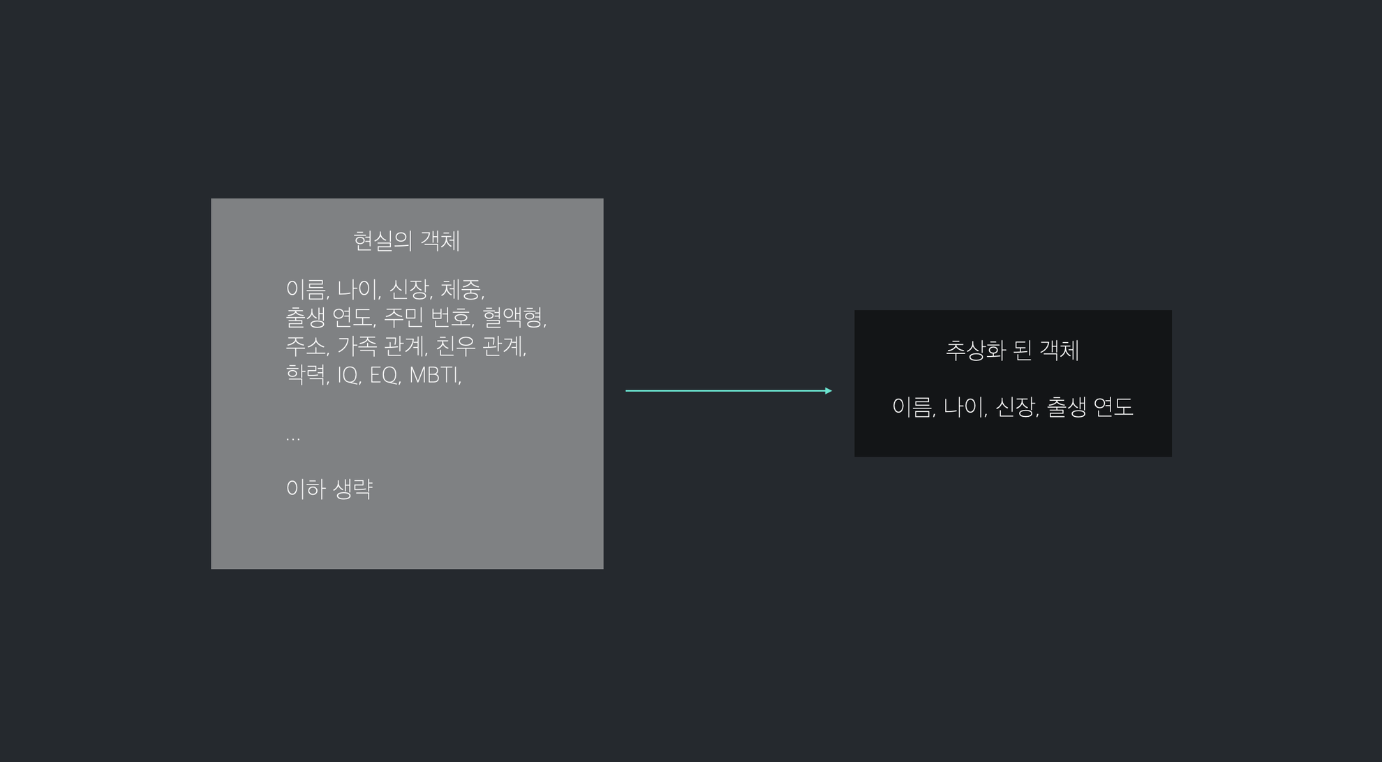
객체 지향의 추상화를 도식화하면 위과 같이 볼 수 있다.
구체적인 것을 간추려서 추상적으로 만드는 것
함수에서의 추상화도 의미는 동일하다.
가정집에서 전등 스위치를 눌렀을 때 실행될 함수를 작성한다고 생각해보자.
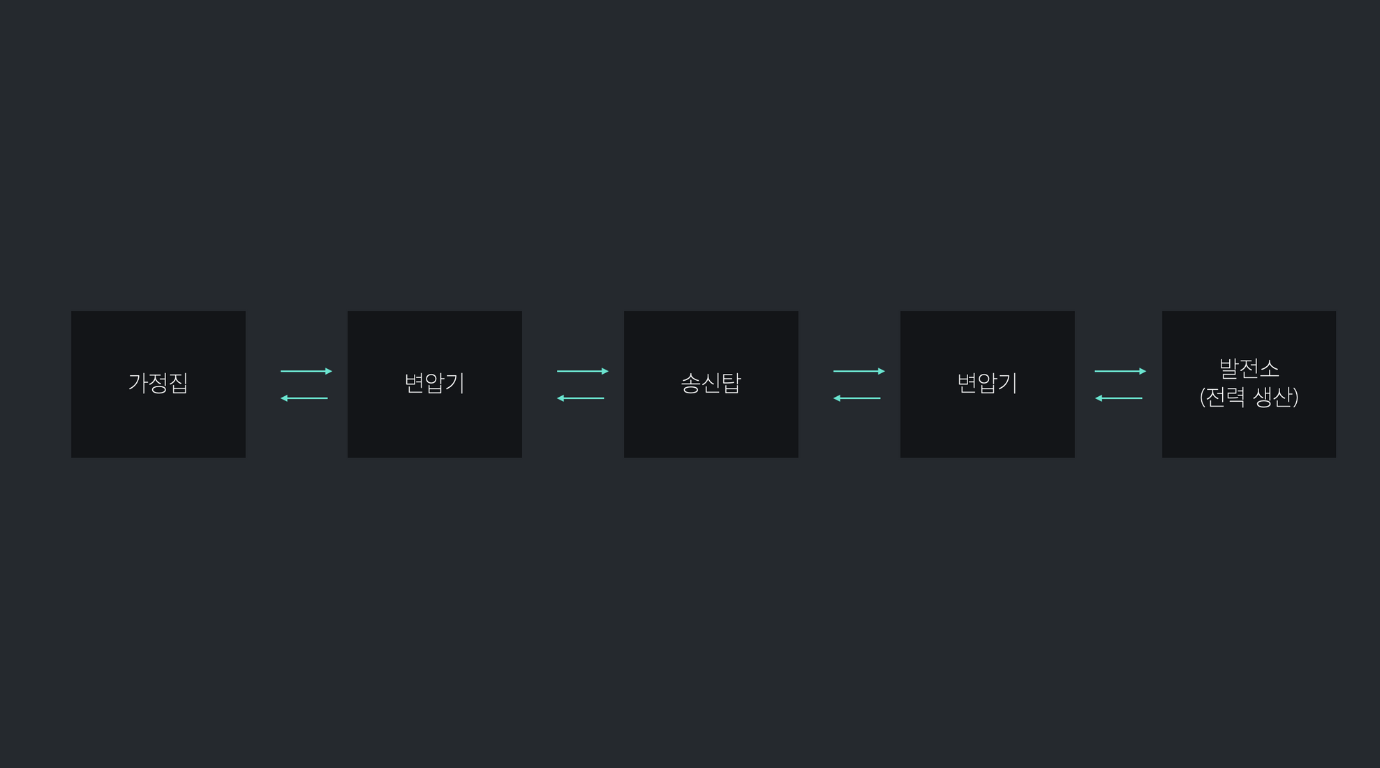
가정집에서 전기를 공급 받으려면 발전소에서부터 수많은 변압기와 송신탑을 거치도록 매우 복잡한 과정을 거칠 것이다.
그러나 대부분의 사람들은 이렇게 자세한 과정을 전혀 모르고 스위치를 누르면 불이 들어온다는 것만 인지하면 아무런 불편함 없이 전기를 공급 받을 수 있다.
대부분의 복잡한 과정이 스위치를 누른다는 아주 간단한 행위로 추상화 되어 있기 때문이다.
함수에서의 추상화도 마찬가지다.
함수 내에 아무리 복잡한 로직이 작성되어 있더라도, 해당 함수를 호출하는 개발자는 함수의 의미와 결과만 파악하면 된다.
turnOnSwitch();turnOnSwitch 함수의 내부 구현이 어떻게 되어 있는지 전혀 모른 채, 호출만 하면 원하는 결과를 얻을 수 있는 것이다.
객체의 의인화에서 봤던 코드도 마찬가지다.
person.pickUp(carKey); // 차 키를 집어든다.
person.put(person.carKey).in(car); // 집어든 차 키를 차에 꽂는다.
person.openDoorOf(car); // 문을 연다.
person.getIn(car); // 차에 탄다.
person.start(car); // 시동을 건다.
person.stepOn(car.pedal); // 엑셀을 밟는다.위와 같이 자동차를 운전할 때 실제로 발생하는 현실 세계의 동작 하나 하나를 그대로 코드로 옮길 경우 매우 복잡하게 느껴졌던 과정을,
car.drive();객체를 의인화 하고 동작(메소드)을 추상화하여 가독성을 크게 높일 수 있었다.
2. 캡슐화(Encapsulation)
간단히 말해서 변수와 함수를 하나로 묶는 것,
즉, 속성과 동작을 클래스로 묶어서 만드는 것이 바로 캡슐화다.
추상화를 통해 현실에 존재하는 사물의 속성과 동작 중에서 필요한 것만 추출했고,
이를 클래스로 옮기면 추상화와 캡슐화를 한 것이다.
class Person {
int age;
String firstName;
String lastName;
int height;
int birthYear;
// 이전에 작성한 생성자 생략
public void eat() {
System.out.printf("%s is eating\n", this.firstName + this.lastName);
}
public void sleep() {
System.out.printf("%s is sleeping\n", this.firstName + this.lastName);
}
public void work() {
System.out.printf("%s is working\n", this.firstName + this.lastName);
}
}앞서 살펴봤던 것처럼 인간을 추상화하여 Person 이라는 클래스를 만들었다.
인간이 가진 모든 속성을 클래스로 묶는 것이 아니라, 우리가 작성하는 프로그램에서 꼭 필요로 하는 속성만 뽑아서 모델링(추상화)을 한 뒤, 클래스로 묶어서 캡슐화를 한 것이다.
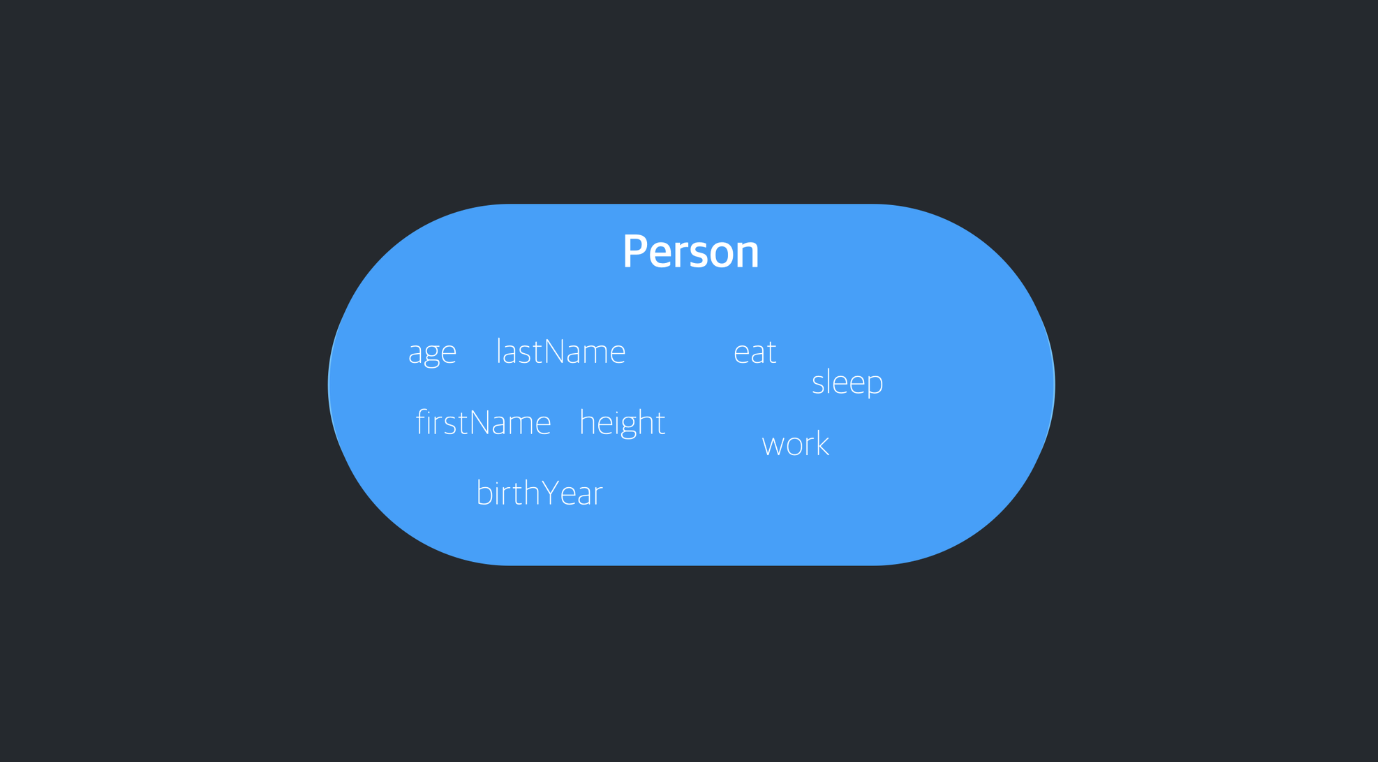
위와 같이 하나의 캡슐 속에 속성과 동작을 담은 이미지를 생각하면 된다.(캡슐이라고 불리는 알약 속에는 수많은 알갱이가 들어있지 않던가.)
추상화는 현실에 존재하는 객체가 가진 구체적인 속성 중, 반드시 필요한 속성만을 추출하고,
캡슐화를 추출한 속성들을 실제로 클래스로 옮겨서 클래스라는 캡슐에 담는 것이다.
이 때, 접근 제어자를 통해 클래스에 담은 속성과 동작들을 외부에 노출하지 않도록 숨길 수 있는데,
이를 정보 은닉이라 부른다.
https://en.wikipedia.org/wiki/Encapsulation_(computer_programming) (opens in a new tab)
위키피디아에 Encapsulation 페이지를 보면 첫 줄에 위와 같이 설명되어 있다.
캡슐화는 데이터(속성)와 데이터를 조작하는 메소드(동작)을 하나로 묶는 것을 일컬으며,
해당 클래스의 일부 데이터, 메소드에 대한 직접적인 접근을 제한할 수 있다.
그렇다고 한다.
해당 클래스의 일부 데이터, 메소드에 대한 직접적인 접근을 제한할 수 있다 라는 부분이 바로 정보 은닉에 대한 이야기다.
Java에 어느정도 익숙해졌다면, 접근을 제한한다는 말을 보고 접근 제어자(Access Modifier)가 바로 떠오를 것이다.
class Person {
private int age;
private String firstName;
private String lastName;
private int height;
private int birthYear;
// 이전에 작성한 생성자 생략
public void eat() {
System.out.printf("%s is eating\n", this.firstName + this.lastName);
}
public void sleep() {
System.out.printf("%s is sleeping\n", this.firstName + this.lastName);
}
public void work() {
System.out.printf("%s is working\n", this.firstName + this.lastName);
}
}
Person p = new Person("John", "Doe", 49);
p.work(); // ok
p.age; // Compile Error위와 같이 private 접근 제어자로 선언된 멤버 변수를 외부에서 접근하려고 시도하면 컴파일 오류가 발생한다.
자바는 개발자가 작성한 소스 코드를 컴파일 하기 전에, 여러 가지 오류를 미리 검사해서 개발자의 실수를 잡아주기 때문이다.
반대로 public 으로 선언된 메소드는 잘 작동할 것이다.
이런 식으로 객체를 생성했을 때, 외부에서 접근할 수 있는 속성, 메소드를 제한하여 외부에서 마음대로 읽고 쓰는 것을 방지할 수 있다.
다음과 같은 이미지를 떠올리면 된다.
이렇게 접근을 제한 했을 때 얻는 이점이 뭘까.
객체는 항상 생성부터 소멸 시점까지 유효한 데이터를 가져야 한다고 했던 것을 떠올려보자.
이를 방지하기 위해 객체를 생성할 때, 생성자 내에서 인자를 검사하는 로직을 작성했었다.
그러나 모든 필드에 접근이 가능하여 객체 생성 이후에 아래와 같이 마음대로 유효하지 않은 값을 넣으면 어떤가.
p.height = 99999;생성부터 소멸 시점까지 유효한 데이터를 가져야 한다는 원칙이 위반되었다.
그래서 아래와 같이 속성에 대한 접근을 private 으로 제한하고,
getter, setter로 읽기, 쓰기를 나눈 것이다.
class Person {
private int height;
// 나머지 속성 및 메소드 생략
public void setAge(int height) {
if (height < 0 || height > 300) {
// 유효하지 않은 키 입력 시 예외 발생
throw new IllegalArgumentException();
}
this.height = height;
}
public int getAge() {
return this.age;
}
}
Person p = new Person("John", "Doe", 49);
p.getAge(); // 49
p.setAge(50);
p.getAge(); // 50
p.age = 50; // Compile Error이제 getAge 로 age 를 읽고, setAge 로 age 를 변경할 수 있다.
setAge 내에서 유효한 age 인지 검사를 해주기 때문에 유효하지 않은 데이터가 들어가는 것을 방지할 수 있다.
class Person {
private String firstName;
private String lastName;
// 나머지 속성 및 메소드 생략
public int getName() {
return this.firstName + " " + this.lastName;
}
}
Person p = new Person("John", "Doe", 49);
p.getName(); // "John Doe"또한 위와 같이 firstName 과 lastName 을 조합하여 실제로 존재하지 않는 name 이라는 속성이 마치 존재하는 것처럼 getName getter를 만들 수도 있다.
해당 객체를 사용하는 개발자는 getter를 호출하여 실제로 존재하지 않는 속성도 존재하는 양 사용할 수 있는 것이다.
class Person {
public int height;
// 나머지 속성 및 메소드 생략
}
Person p = new Person("John", "Doe", 49);
if (height < 0 || height > 300) {
// 유효하지 않은 키 입력 시 예외 발생
throw new IllegalArgumentException();
}
p.height = height;물론 getter, setter를 사용하지 않고, 위와 같이 수동으로 일일이 검증을 해줄 수도 있다.
// file1
Person p = new Person("John", "Doe", 49);
if (height < 0 || height > 300) {
throw new IllegalArgumentException();
}
p.height = height;
// file2
Person p2 = new Person("John", "Doe", 49);
if (height < 0 || height > 300) {
throw new IllegalArgumentException();
}
p2.height = height;
// file3
Person p3 = new Person("John", "Doe", 49);
if (height < 0 || height > 300) {
throw new IllegalArgumentException();
}
p3.height = height;
// ... file1000그럼 1000개의 파일에서 객체를 생성한다면 어떨까.
그리고 어느 날, 키가 310인 사람이 세계 최장신 신기록을 세워서 height를 310 이하로 변경하도록 요구 사항이 들어온다면.
1000개의 파일에서 1000개의 조건문을 변경해야 할 것이다.
게다가 이렇게 반복적으로 똑같은 코드를 작성하게 되면 실수로 검증 로직을 빠뜨릴 위험이 존재한다.
오랫동안 해당 코드를 관리한 사람이라도 실수할 여지가 있는데,
규모가 커서 새로운 개발자가 대거 들어오고 나가는 환경이라면 실수가 발생할 가능성은 더욱 더 커질 것이다.
아무런 설명이 없는데 키를 0 ~ 310으로 검증하는 로직이 들어가야 한다는 사실을 어떻게 바로 알 수 있을까.
생성자 내에서 검증을 했다면 새로 들어온 사람도 세부 검증 로직을 알 필요가 없을 것이고,
요구 사항이 변경 되더라도, 1000개의 파일이 아닌 생성자 하나만 변경하면 끝날 일이다.
객체 지향은 인간이 생각하는 방식으로 직관적인 코드를 작성하게끔 만드는 역할도 하지만,
이처럼 재사용성을 향상시켜 유지 보수가 용이해지고, 실수를 줄여주기도 한다.
3. 상속(Inheritance)
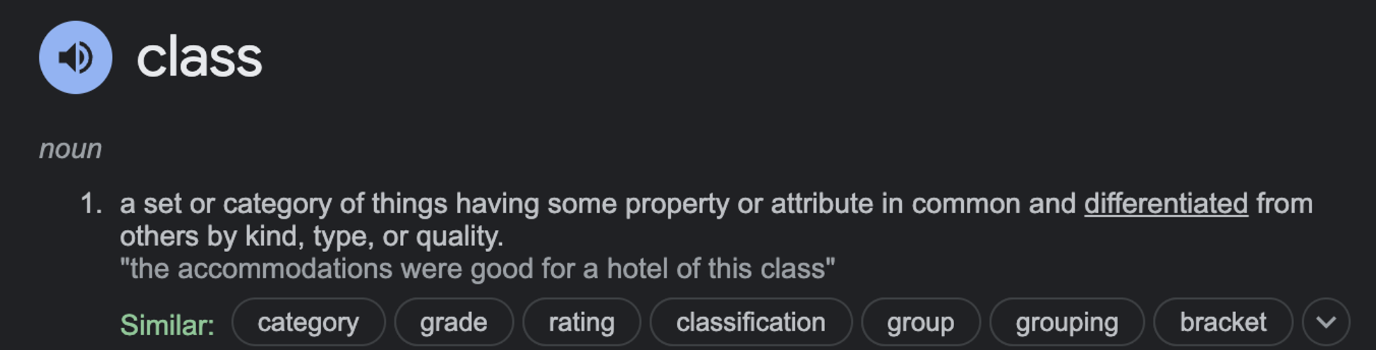
객체 지향 언어에서 주로 사용되는 class는 위의 의미일 것이다.
고유한 속성을 가져 다른 것들과 구별되는 사물의 집합이라고 하는데,
class를 종으로, instance를 해당 종에 대한 개체로 생각하면 좀 더 이해가 쉬울 것 같다.
인간이란 종 안에 홍길동이라는 개체가 속한다.
이 경우, 인간은 class고 홍길동은 instance가 된다.
코드로 표현하면 다음과 같다.
Person 홍길동 = new Person("홍길동");비생명체라면 종을 범주, 혹은 분류라고 생각하면 되겠다.
이번엔 Person 대신 Animal class를 만들어보겠다.
class Animal {
int age;
int height;
int weight;
void sound() {
// ...
}
}모든 동물은 나이와 키, 체중을 속성으로 가지며 소리를 낼 수 있다.
그런데 Person 과 달리 Animal 은 너무 다양한 종을 포함하고 있다.
구체적이지 않고 추상적이다.
다리가 2개인 인간과 4개인 강아지는 모두 Animal 로 분류되지만,
다른 속성과 동작을 갖는다.
강아지와 고양이도 마찬가지로 서로 다른 속성과 동작을 가지기 때문에
Animal 이라는 추상적인 class만으로는 이를 표현할 수 없고,
보다 구체적인 Dog , Cat 으로 class가 나뉘어야 하는 것이다.
class Dog {
int age;
int height;
int weight;
void bite() {
System.out.println("물다");
}
}
class Cat {
int age;
int height;
int weight;
void climb() {
System.out.println("나무에 오르다");
}
}이제 강아지냐 고양이냐에 따라 고유의 동작을 갖게 되었다.
그러나 둘 다 동물이기 때문에 겹치는 속성이 존재한다.
이 때 상속을 통해 중복을 제거할 수 있다.
class Animal {
int age;
int height;
int weight;
}
class Dog extends Animal {
void bite() {
System.out.println("물다");
}
}
class Cat extends Animal {
void climb() {
System.out.println("나무에 오르다");
}
}class 뒤에 extends 로 상속 받을 class를 지정하면 해당 class가 가진 모든 속성을 갖게 된다.
Dog 와 Cat 은 모두 Animal 을 extends 했기 때문에, age , height , weight , sound 를 작성하지 않았지만 모두 갖게 되는 것이다.
이 때, Dog 와 Cat 은 Animal 의 속성과 동작을 모두 물려 받았기 때문에 자식 클래스(Child)라 부르고, Animal 은 부모 클래스(Parent)가 된다.
혹은 자식 클래스(Child)를 파생 클래스(Derived), 부모 클래스(Parent)를 기반 클래스(Base) 라고도 하며,
Dog 와 Cat 은 같은 부모 클래스를 갖기 때문에 형제 클래스(Sibling)라고 한다.
class와 속성이 늘어날수록 상속을 통한 중복 제거는 것은 유지 보수에 있어서도 큰 이점이 될 것이다.
중복되는 속성을 한 곳에서 관리하면 나머지 모든 곳에 적용되기 때문에,
나중에 속성을 변경할 때, class 수가 N이면 N배 만큼 변경할 코드가 줄어들 것이다.
중복을 줄일 수 있다는 점이 상속의 명확한 장점이지만, 동시에 이는 치명적인 단점이 되기도 한다.
상속의 문제점
1. 캡슐화 위반 및 강한 결합
우선 캡슐화를 위반한다.
Parent가 a, b, c, d, e라는 property를 갖고,
Child가 x, y, z라는 property를 갖는 경우,
Child의 구현은 다음과 같다.
public class Child extends Parent {
private int x;
private int y;
private int z;
}Child는 x, y, z만 갖고 있는 것처럼 보인다.
그러나 보이지 않더라도 Parent를 상속 받았기에 a, b, c, d, e도 존재하고 있을 것이다.
이 사실을 인지하기 위해 Child 뿐만 아니라 Parent로 한 번 indirection을 거쳐서 구현을 까봐야 한다.
즉, 자식 클래스가 부모 클래스의 내부 구현에 의존하는 형태가 된다.
부모 클래스의 명세를 봐야만 자식 클래스를 제대로 파악할 수 있으며,
부모 클래스에서 a를 제거한다면 이에 의존하는 모든 자식 클래스가 영향을 받는다.
부모와 자식이 강하게 결합되는 것이다.
depth가 1인 상속이라면 그나마 괜찮을 수 있지만, 만약 Parent - Child - GrandChild - GrandChild2 - GrandChild3으로 이어지는 매우 깊은 depth를 갖는 상속이라면 이야기는 또 달라지게 된다.
GrandChild3은 Parent ~ GrandChild2 모두를 상속 받기 때문에 이 중 어떤 클래스라도 변경 된다면 영향을 받게 된다.
언제든지 공격 당할 수 있는 포지션이라고 생각할 수 있다.
또한 어떤 필드가 있는지 정확히 파악하기 위해 총 5개의 클래스를 까봐야 한다.
마치 5중 포인터를 역참조 하며 거슬러 올라가듯, 너무 많은 indirection이 발생하여 이해하기 어렵다.
또한 상속 depth가 깊을 수록 쓸 데 없는 필드나 메소드를 자식 클래스가 갖게 될 확률도 증가할 것이다.
사용하지 않을 필드나 기능은 배제하는 것이 메모리를 절약하고 협업 시 혼동을 주지 않을 것인데, 이를 정면으로 부정하는 셈이다.
일부 C++ 등의 언어에서는 다중 상속의 문제도 있지만, 보통은 다중 상속을 배제하는 추세이기 때문에 Java에서는 이러한 걱정은 없다.
그래서 최근에 출시된 언어들은 아예 상속이라는 개념을 배제하는 경우도 더러 있다.
대표적인 예시가 Go와 Rust다.
2010년 근방에 출시된 두 언어는 신생 언어라고 볼 수 있는데, 상속이 아예 존재하지 않는다.
의도적으로 배제된 채로 언어가 디자인 되었는데, 위에서 말한 단점들이 상속이 주는 장점보다 크다고 여겼기 때문이다.
상속 대신 컴포지션을 사용하라는 격언이 있다.
컴포지션은 단순히 다른 객체를 필드로 포함시키는 것인데,
이를 통해 두 객체 간의 결합을 약화 시킬 수 있으며, 상속보다 훨씬 유연하게 마치 블록을 조립, 해제하듯 다룰 수 있다.
// inheritance
public class Phone extends Battery {
// ...
}
public class Phone {
// composition
private Battery battery;
// ...
}코드 예시를 보면 알겠지만 개념은 매우 간단하다.
Java의 모든 객체는 포인터 연산이 불가한 포인터, 레퍼런스이기 때문에 컴포지션은 Heap 상에 저장되어 메모리 연속체 형태로 구성되는 상속보다 약간의 성능 저하가 있다는 부분은 알아두자.
상속을 매우 나쁘게 말했지만 OOP에서 배제할 수 없는 개념이기도 하다.
상속의 포함 여부로 OOP 언어인지 아닌지를 구분하는 경우도 있다.
또한 Go나 Rust는 Java와 달리 Stack에 구조체를 쌓을 수 있기 때문에 컴포지션으로도 최적화가 가능하다는 점도 한 몫 했던 것 같다.
상속은 성능이 필요한 지점에서 사용 + depth를 얕게 유지하는 등의 가이드라인을 잡고 적절하게 사용하는 것이 중요할 것이다.
4. 다형성(Polymorphism)
위에서 봤던 예제를 그대로 활용하여 간단하게 설명하겠다.
강아지와 고양이는 동물이라는 범주에 속한다.
뿌리는 같기에 공통 속성이 존재하지만, 동시에 완전히 같은 종은 아니기 때문에 다른 부분도 존재한다.
이를 보다 구체적인 class로 나누어서 고유의 속성과 동작을 추가함으로 해결했었다.
그러나 문제는 같은 동작을 함에도 불구하고 결과가 다를 때다.
강아지와 고양이는 둘 다 소리를 낼 수 있다.
그러나 내는 소리, 즉 결과는 다르다.
이미 모든 동물은 소리를 낼 수 있다고 가정했기 때문에 Animal 에 sound 메소드를 작성했고,
Dog , Cat 은 모두 Animal 을 상속 받았기 때문에 같은 sound 메소드를 호출하게 될 것이다.
같은 메소드를 호출하기 때문에 소리도 같아야 한다.
그러나 현실에서는 강아지와 고양이는 서로 다른 소리를 내기 때문에
sound 의 구현이 서로 달라져야 한다.
class Dog extends Animal {
@Override
void sound() {
System.out.println("멍");
}
}
class Cat extends Animal {
@Override
void sound() {
System.out.println("냥");
}
}이제 강아지냐 고양이냐에 따라 sound 의 구현이 달라져서 강아지는 강아지 소리 내고 고양이는 고양이 소리를 낸다.
여기까지만 보면 다형성이 어디다 쓰는 것인지 조금 감이 안 올 수도 있다.
다형성을 통해 다양한 분기 처리가 필요한 if, switch을 대체하는 경우가 좋은 예시가 될 것 같다.
예를 들어 알림을 보내는 send라는 함수가 존재하고, 전송 채널의 종류가 email, message, push_notification, voice_message 4가지 종류가 있다고 해보겠다.
분기 처리를 하면 다음과 같은 코드가 될 것이다.
public void send(String media, String dest) {
if (media == "email") {
// 로직 100줄
} else if (media == "message") {
// 로직 100줄
} else if (media == "push_notification") {
// 로직 100줄
} else if (media == "voice_message") {
// 로직 100줄
}
// 확장 시 로직 추가
}간단한 로직의 경우 위와 같이 분기 처리만으로 충분하지만,
로직이 복잡해진다면 코드를 읽기가 어려워 질 것이다.
로직이 100줄이라고 되어 있는데, 그럼 send 메소드는 총 400줄이 넘어간다.
이러면 어떤 media가 있는지 보기가 힘들 것이다.
또한 전송 매체가 늘어날 때마다 기존 send를 바꿔야 하기 때문에 확장에 그다지 좋은 구조라고 할 수 없다.
public interface Sender {
void send(String dest);
}
public class EmailSender extends Sender { ... }
public class MessageSender extends Sender { ... }
public class PushNotificationSender extends Sender { ... }
public class VoiceMessageSender extends Sender { ... }
// 확장 시 클래스 추가
List<Sender> senders = [ emailSender, messageSender, ... ];
for (Sender sender : senders) {
sender.send(dest);
}이 때, 상속을 통해 다양한 Sender를 상속하는 클래스를 여럿 만든다.
EmailSender, MessageSender, PushNotificationSender, VoiceMessageSender는 모두 Sender의 자식 타입이므로,
부모 타입인 Sender로 형변환이 가능하다.
그래서 List<Sender>에 넷 중 어떤 타입이 오더라도 함께 넣을 수 있다.
(만약 List<EmailSender>와 같은 구체 타입의 리스트였다면, MessageSender, PushNotificationSender 등 다른 타입들이 함께 저장될 수 없었을 것이다.)
그리고 구체적인 로직은 각 클래스의 send 메소드에 작성한다.
그럼 어떤 Sender가 들어오더라도 sender.send(dest)를 호출하는 것 만으로 처리가 완료된다.
확장 시에 기존 코드를 전혀 건드리지 않고, Sender를 상속하는 새로운 클래스를 만들면 된다.
기존 코드 확장 시 변경이 필요 없으므로 OCP를 지킨다고 볼 수 있다.
또한 String으로 media를 입력 받으면 오타로 인한 오류가 발생할 수 있는데, 클래스로 media를 구분하다 보니 타입을 통해 컴파일 타임에 오타를 잡아줄 수 있다는 장점도 있다.
EmailSender를 Sender 타입으로 형변환 해도 다형성에 의거하여 최초 생성 시에 사용된 구체 타입의 메소드를 호출하므로 형변환은 메소드 호출에 아무런 영향을 미치지 않는다.
이러한 형태의 함수 호출을 dynamic dispatch라고도 하는데, 이를 메모리 관점에서 보면 또 흥미롭지만 주제를 벗어나므로 나중에 다루도록 하겠다.